
하이퍼파라미터 최적화.. 중요한 건 알겠는데.. 일일히 하는게 번거롭네?
하이퍼파라미터의 최적화는 기계학습의 중요한 태스크 중에 하나입니다.
하이퍼파라미터를 어떻게 선택하는 가에 따라 Overfit 이 된 모델이 될 수 도 있고, Underfit 모델이 될 수 있습니다.
하지만 같은 종류의 모델을 사용하더라도 학습하는 데이터에 따라서 하이퍼파라미터의 값은 상이합니다.
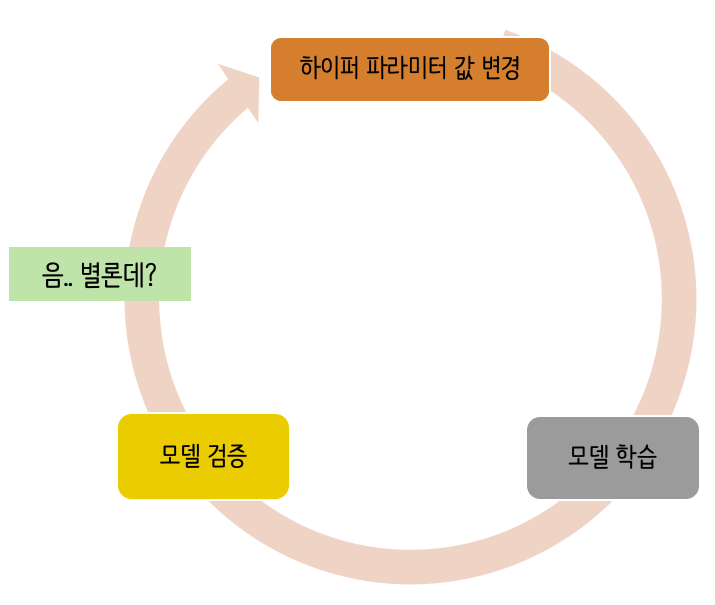
우리는 최적화된 파라미터를 찾기 위해서 값을 조정하면서, 모델을 수행을 하고 모델을 검증을 합니다.
그리고 이걸 결과가 좋을 때까지 하이퍼 파라미터 값을 재변경해서 다시 학습 및 검증을 하는 과정을 반복합니다.
근데 이 과정이 생각보다 귀찮습니다.
Optuna : 하이퍼파라미터 최적화 프레임워크
Optuna는 하이퍼파라미터 최적화 태스크를 도와주는 프레임워크입니다.
파라미터의 범위를 지정해주거나, 파라미터가 될 수 있는 목록을 설정하면 매 Trial 마다 파라미터를 변경하면서, 최적의 파라미터를 찾습니다.
하이퍼파라미터의 범위나 목록은 아래의 방법으로 설정할 수 있습니다.
- suggest_int : 범위 내의 정수형 값을 선택합니다.
n_estimators = trial.suggest_int('n_estimators',100,500)
- suggest_categorical : List 내의 데이터 중 선택을 합니다.
criterion = trial.suggest_categorical('criterion' ,['gini', 'entropy'])
- suggest_uniform : 범위 내의 균일 분포를 값으로 선택합니다.
subsample = trial.suggest_uniform('subsample' ,0.2,0.8)
- suggest_discrete_uniform : 범위 내의 이산 균등 분포를 값으로 선택합니다.
max_features = trial.suggest_discrete_uniform('max_features', 0.05,1,0.05)
- suggest_loguniform : 범위 내의 로그 함수 선상의 값을 선택합니다.
learning_rate = trial.sugget_loguniform('learning_rate' : 1e-6, 1e-3)
소스 코드
이전 포스팅에서 사용했던 XGBoost Regressor를 최적화 하는데 사용한 소스코드 입니다.
전체 소스코드는 https://www.kaggle.com/ssooni/xgboost-lgbm-optuna 를 참고하시면 됩니다.
매 Trial 마다 수행할 함수를 작성합니다.
함수 내부에는 하이퍼파라미터의 값을 정의하는 부분과 모델을 학습하는 부분을 작성하고 Loss Metric의 결과를 반환합니다.
이제 아래의 소스를 참고해서 optuna를 사용해서 최적의 파라미터를 찾아봅시다.
최적의 파라미터는 study.best_trial.params 에 저장되어 있습니다.
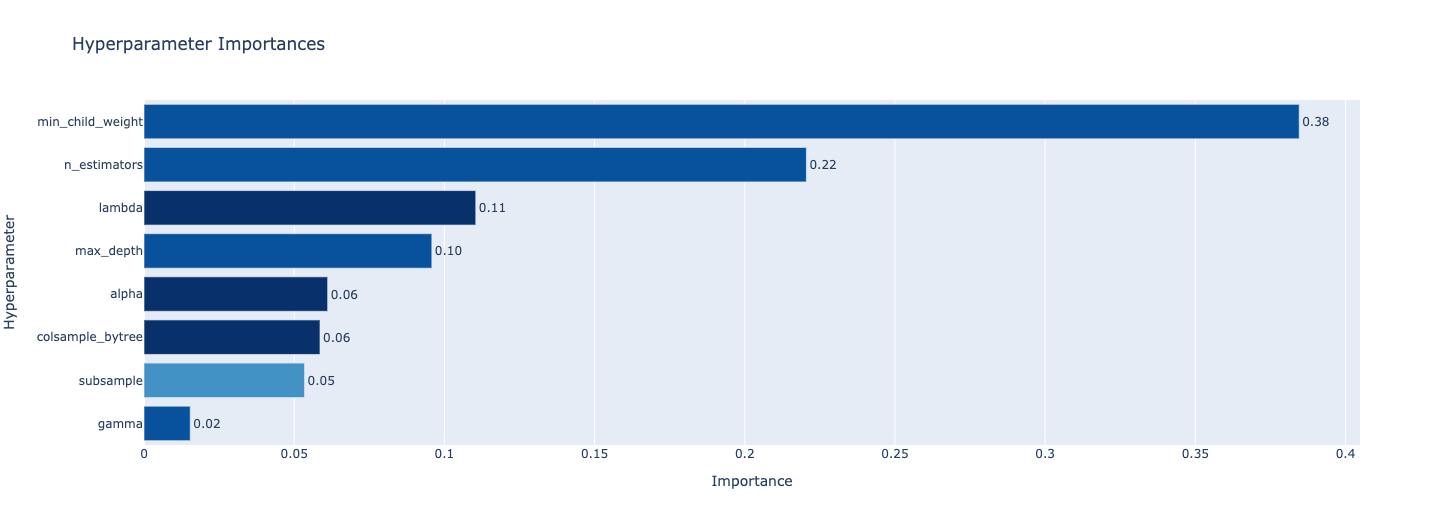
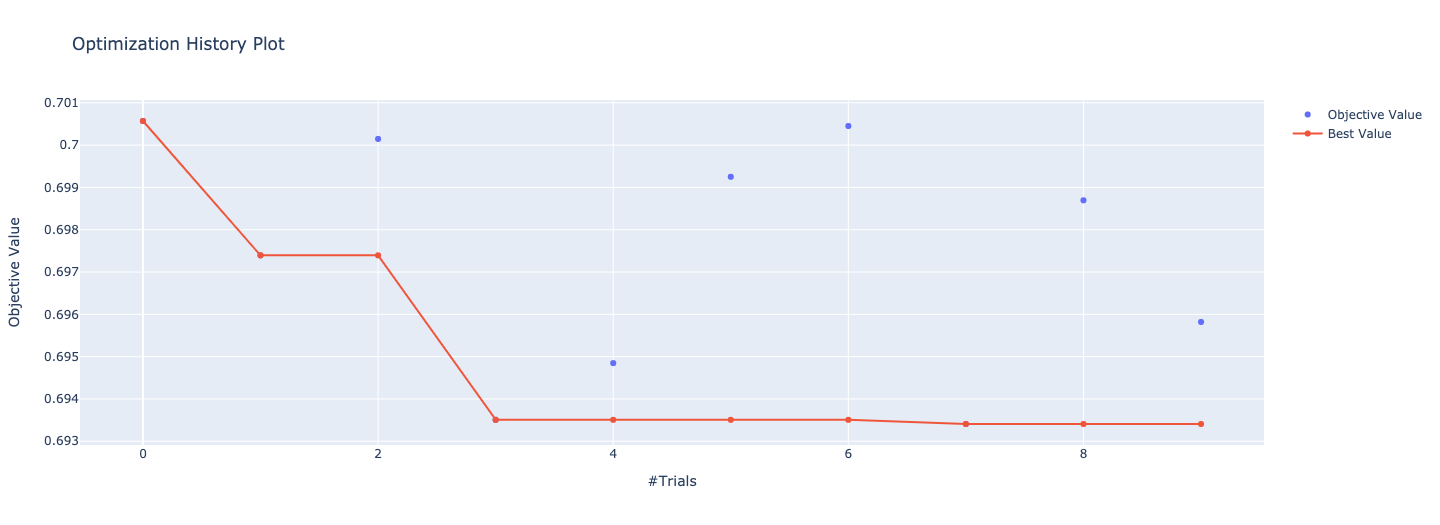
optuna는 추가적으로 학습하는 절차를 확인할 수 있는 시각화 툴도 제공합니다.
다양한 시각화 기법을 제공하지만 저는 매 Trial 마다 Loss가 어떻게 감소되었는 확인 할 수 있는 함수와
하이퍼 파라미터 별로 중요도를 확인할 수 있는 함수를 소개 합니다.
도움이 되셨으면, 아래의 공감 버튼을 눌러주세요.
공감 버튼은 작성자에게 큰 동기부여가 됩니다.
'Data Mining' 카테고리의 다른 글
| XGBoost 요약 정리 (0) | 2021.02.07 |
|---|---|
| GRU(Gated Recurrent Unit) (0) | 2021.01.17 |
| [Python] 공공데이터 API 사용기 (feat 미세먼지) (3) | 2019.01.15 |
| [Python]DBSCAN 클러스터링 (with 카톡 대화) (2) | 2018.12.23 |
| [Python] Word2Vec으로 관련 키워드 찾기 (with 카톡 대화) (3) | 2018.12.15 |
