
이전 포스팅 : 2019/01/15 - [Data Mining] - [Python] 공공데이터 API 사용기 (feat 미세먼지)
소소한 근황 소개
미세먼지 API를 사용하는 것을 이후로 SVM이나 Correlation 적용하는 등의 시도를 하였으나,
생각보다 결과도 좋지 않았고 내가 알고 있는 지식의 한계가 와서... 대학원을 가버렸다(응?)
또 약간의 지식을 배웠으니까 블로그에 정리를 해봅니다.
Sequence Model
앞선 포스팅에서 매 시간마다 측정한 미세먼지 및 기상 데이터를 수집을 하였습니다.
미세먼지나 기상데이터의 특징이라고 한다면 시간에 따른 순서가 있는 데이터라는 점입니다.
이러한 종류의 데이터를 모델링하는 걸 Sequence Model이라고 하며 RNN, LSTM, 이번에 다룰 GRU 등이 있다.
Sequence Model에 주로 적용하는 데이터는 주식이나 텍스트 등이 있다.
(우리가 사용하는 언어도 어순이 있기 때문에 Sequence Model 대상이다.)
일반적으로 사용하는 신경망에서 Sequence Data 를 사용하기 어려운 이유는 2가지입니다.
입력 데이터와 출력 데이터의 길이가 가변적이다.
대표적으로 CNN은 입력값이나 출력값의 길이가 모델을 학습하거나 적용할 때 동일합니다.
하지만 우리가 주로 보는 동영상이나 책을 입력 데이터로 한다면 각각의 데이터의 길이가 다른데,
이러한 점은 일반적인 인공 신경망 알고리즘에는 적합하지 않은 데이터입니다.
(일부 논문에서는 0으로 부족한 공간을 채워서 연구한 사례가 있긴 합니다.)
일반적인 신경망 알고리즘에서는 데이터의 순서를 반영하지 않습니다.
데이터를 섞어도 학습 결과가 크가 변화하지 않습니다.
즉, 데이터의 선후 관계가 전혀 반영이 되지 않는다는 점이 한계입니다.
RNN의 구조
뒤에서 자꾸 무언가를 준다..
RNN의 학습하는 과정을 도식을 하면 아래와 같이 보통 표현합니다.

파란 색으로 부분을 cell 이라고 합니다.
각각의 cell은 매 단계 마다 일렬로 입력되는 input x와 이전 단계의 결과로 산출된 hidden 값 h를 입력으로 받고 출력으로 예측 값인 y 와 다음 단계로 전달할 hidden 값을 전달합니다.
매 단계마다 이전 단계에서 만들어진 hidden 값을 사용하여 y 값을 생성하기 때문에
입력 값의 순서가 다르면 hidden 값 역시 다르기 때문에 앞서 말한 선후 관계가 반영되지 않은 문제점을 해결할 수 있습니다.
또한 RNN은 다양한 Input 과 Output 의 구조를 가질 수 있습니다.
1:N, N:M, N:1 등의 다양한 구조의 데이터를 적용합니다.
GRU : Gated Recurrent Unit
RNN은 단점이 있습니다. Cell 내부에서는 실제로 소수점 단위의 계산이 이뤄지고 있고 그 결과로 h 값이 발생하는데,
Sequence가 너무 긴 데이터의 경우에 0에 가까운 값이 오고 가게 되어 컴퓨터가 계산할 수 없는 작은 수로 수렴하게 되는 문제가 있습니다.
Gradient Vanishing 으로 불리는 이 문제는 이전 단계의 정보를 선택적으로 학습을 하는 즉, "줄 건 줘" 방식으로 계산하는 LSTM이나 GRU를 통해 개선이 되었습니다.
그리고 이전 단계의 데이터의 반영과 현재 데이터에 대한 반영의 비율을 Gate 를 통해 제어를 합니다.
GRU는 Reset / Update 두 종류의 게이트를 사용해서 학습하는 모델입니다.
Reset Gate
Reset Gate 에서는 이전 단계의 Hidden status 값과 현 단계의 x 값을 Sigmoid 함수에 적용하여 0 ~ 1 사이의 값을 얻습니다.
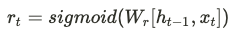
이 값을 이용해서 과거(이전 데이터)의 Hidden 정보를 현재의 정보를 구하는데 얼마만큼 반영 할 것인지 정합니다.
Update Gate
Update Gate 에서도 이전 단계의 Hidden status 값과 현 단계의 x 값을 Sigmoid 함수에 적용하여 0 ~ 1 사이의 값을 얻습니다.
물론 Reset Gate의 Weight 와 다른 Weight를 이용해 계산합니다.
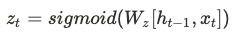
이 값을 이용해서 전체 데이터의 양을 1로 했을 때 현재의 정보를 반영할 비율을 $z_t$, 과거의 정보를 반영할 비율을 $1-z_t$ 로 합니다.
이제 현재의 정보를 아래의 식을 이용해서 구합니다.
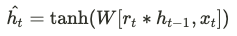
Reset Gate에서 구한 $r_t$를 이용해서 현재 정보를 얻습니다.
마지막으로 현재의 HIdden Status를 과거의 Hiddent Status와 현재의 정보를 앞서 구한 비율 $z_t$ 를 적용하여 계산 후 다음 단계로 전달합니다.
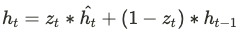
Pytorch 로 적용 해보기
전체 소스 코드 : https://github.com/ssooni/data_mining_practice/blob/master/dust_weather/GRU.ipynb
class GRU(nn.Module):
def __init__(self, n_layers, hidden_dim, input_dim, n_classes=1, dropout_p=0.2):
super(GRU, self).__init__()
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p)
self.gru = nn.GRU(input_dim, self.hidden_dim, num_layers=self.n_layers, batch_first=True, dropout=dropout_p)
self.fc = nn.Linear(self.hidden_dim, n_classes)
def forward(self, x):
h0 = self._init_state(x.size(0))
out, (hn) = self.gru(x, (h0.detach()))
out = self.fc(out[:, -1, :])
return out
def _init_state(self, batch_size=1):
weight = next(self.parameters()).data
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(DEVICE)
전체 소스코드와 실행 결과를 GitHub 에 올려 두었습니다.
매 시간 측정된 날씨 데이터와 미세 먼지 데이터를 이용해서 예측을 해보는 것을 해보았습니다.
실습용으로 사용할려고, 전처리도 간단하게 하고 프로그램도 간단하게 구현했습니다.
참고용으로만 사용하시고, 원하는 도메인에 적절하게 적용하세요
> 공감 버튼은 작성자에게 큰 동기부여가 됩니다.
'Data Mining' 카테고리의 다른 글
| Optuna 간단 메뉴얼 (1) | 2021.02.08 |
|---|---|
| XGBoost 요약 정리 (0) | 2021.02.07 |
| [Python] 공공데이터 API 사용기 (feat 미세먼지) (3) | 2019.01.15 |
| [Python]DBSCAN 클러스터링 (with 카톡 대화) (2) | 2018.12.23 |
| [Python] Word2Vec으로 관련 키워드 찾기 (with 카톡 대화) (3) | 2018.12.15 |
